
Since machine learning tries to emulate the way humans learn, what better way to understand this field than to understand how humans actually learn?
Just the Stats, Ma'am
People learn through a process called empiricism. This is basically where a person makes a bunch of observations and then tries to draw conclusions about his/her surroundings based on those observations.
Here’s an example. You’re an avid coupon clipper. Everyday, you search numerous newspapers for coupons. You go online and download even more coupons. Because you’re diligent, you start to notice a pattern — certain stores would offer much bigger discounts at certain times of the year, like just after major holidays, or two months before the seasons change. You conclude that you can save a bunch of money by visiting these stores at specific times of the year.
Empiricism is by definition statistical. This is the reason why machine learning is chock full of statistical equations. All those equations describe mathematically what actually goes on in the brain of a person while learning. In order to simulate a human brain, a machine by necessity needs to utilize statistics, too.
Our Brains Are Amazing, Aren't They?
You Know What? We're  Amazing!
Think about what this means. What does it mean? Well, it literally means that you have the ability to do advanced statistics in your head! Yep, thaat’s riightt! Whenever you’re learning something, your brain is actually executing a series of incredibly complicated calculations.
Even little babies and animals are innately good at math. Yes, you read that right. Little babies and animals. Babies have excellent facial recognition software, which apparently comes prenatally installed. And the next time you play fetch with a dog, pay attention to the path it takes to go after the object you throw. You’ll notice that the dog will almost always select the optimal path to get there — which can only be determined with calculus.
And no, mathematical equations are not bouncing around in your head. Thank goodness for that! Having all those symbols with sharp points and jagged edges slamming against your soft brain tissue would make things really messy. Instead, your amazing brain does these calculations biochemically. As a result, your brain can actually do math a million times faster than it otherwise would be able to if it has to rely on equations.
If you’ve ever had difficulty in math class, it isn’t because you “suck at math.” Dishearteningly, I hear people say this all the time. NOBODY SUCKS AT MATH. What actually sucks is the awkward symbolic language we’re forced to use. It was invented just so we can do math on paper — which unfortunately, is a lot less efficient than doing it in our brains.
I mean, “+” represents addition. Seriously? No one could find a more intuitive symbol than a cross sign? Was Jesus doing addition when he died on the cross or something? And what the heck is “∐” supposed to mean? Or this, “∀”? —— Yeesh.
Flaws of the Empirical Mind
So yes, our brains are phenomenal. But, unfortunately, they’re not without problems. The one big failing of empirical learning is that oftentimes, you end up jumping to the wrong conclusions. Your mind frequently creates associations where none actually exist.
Let’s revisit the coupon-clipping example. You don’t realize that there is another store offering much larger discounts than what you’ve been able to find. It flies under your radar because this store advertises via flyers instead of online or in newspapers. And the seemingly lower prices you’re paying for are actually the result of you buying lower-quality items and not so much because of coupon discounts. So, in reality, you’re not saving any money at all.
Here’s another example. It’s a lazy Saturday afternoon, and you’re sitting on your front porch. At one point, a bunch of horses gallop by. Seven white, two black, and one brown. Let’s say you don’t know much about horses. You may conclude, based on your observation, that 70% of the horses in the world are white-colored. Now, zoologists have assured me that white horses are very rare. But your observation gives you the wrong impression, and you think white horses are a lot more common than they actually are.
Statisticians spend a lot of time trying to improve our ability to draw valid conclusions. All those fancy-schmancy stuff they talk about, such as normal distributions, statistical significance, observational power, etc., are all attempts to filter out the bad conclusions and keep only the good ones.
A statistician runs up to you and say, “Whoa, whoa! Don’t be so quick to conclude that 70% of all horses in the world are white!”
You ask, “Why not?”
The statistician responds, “Well, your conclusion is much more likely to be valid if you wait ’til you have many more observations.”
You go, “And how many more observations should that be?”
The statistician says, “A safe number would be at least 20 randomly observed groups of horses galloping by your house.”
You’re exasperated, “Uh, first of all, I’m not exactly sure what you mean by ‘randomly’. A bunch of horses running around this neighborhood is definitely NOT a random event. And second, what’s the chances that nineteen more batches of horses will be galloping past me while I’m sitting here on my porch? You’re basically telling me not jump to any conclusions at all! I’m sorry, but I can’t do that. I’m human, and that’s what we do — jump to conclusions!”
Here’s a third example. You’re meeting a friend. When you see him, you notice he’s wearing a blue shirt, and you exclaim, “Oh, I didn’t know you own a blue shirt!”
Unfortunately, your empirical mind has led you astray once again. Just because your friend wears a blue shirt does not logically imply that he owns a blue shirt. Turns out, your friend borrowed a yellow shirt from his co-worker and painted it blue just to make you think he owns a blue shirt.
What kind of friend would go to such lengths to deceive you? The kind of friend who deserves to get beaten senseless. But you missed a golden opportunity to beat your friend senseless, simply because you jumped to the wrong conclusion.
Prejudice, bigotry, bias, gossip, rumors, misunderstandings, hysteria, superstition — these are all flaws of the empirical mind. Unfortunately, we have to deal with these issues in machine learning, too.
And yes, even machine learning algorithms can become superstitious. There’s always a possibility that the machines will insist that the New York Yankees‘ right fielder Aaron Judge will need to wear the same pair of underwear for the rest of the season for him to continue his home run hitting streak. This a nasty business, but we have to take the bad if we want the good that machine learning can offer.
Painting It Black Instead
Sadly, post-traumatic stress disorder is also a by-product of empirical thinking. When a person experiences severe trauma, his brain does everything it can to make sure he never gets into a situation like that again. This includes linking every piece of sensory information it’s received during that event to the trauma itself, no matter how innocuous or irrelevant the information may be. When it detects the same or a very similar sensory signal again, it immediately goes into “fight-flight-or-freeze” mode.
A war veteran, for instance, may hear a car backfiring and think it’s gunfire. Or, mistake a stone rolling down a hill as a grenade about to go off. For a child abuse victim, the smell of a certain perfume may trigger flashbacks to the abuse his mom inflicted upon him when he was a child.
Do Not Attempt To Grow A Brain —— 'Cause You're Already Born With One!
If empirical thinking is so problematic, why in the world did Mother Nature evolve us to have empirical minds? For one reason, and one reason only — Speed. The very impulse that causes us to constantly jump to conclusions is ironically the empirical mind’s greatest strength.
We live in an extremely dangerous world. When our lives are under constant threat, it’s actually ten times better to flash false positives than false negatives. You can recover from false positives — but even one false negative can become fatal.
- “What’s that yellow fuzz sticking out of the grass? Run! It’s definitely a lion! Oh, wait, it’s just tumbleweed.”
- “What’s that rumbling sound coming from behind the tree? Run! It’s definitely a lion! Oh, wait, it’s just Dad snoring really loudly.”
- “A lion’s top speed is 50 miles an hour, so I should be safe on this bus that never seems to go below 50.”
Okay, that last one probably has less to do with empirical thinking and more to do with a lack of situational awareness. You may be embarrassed that you got hysterical over tumbleweed — but at least you’re alive. And your dad may be offended that you mistook him for a lion — but at least you’re alive, and you can apologize.
Had you hesitated, though, and it turned out that the yellow fuzz or the rumbling noise really was a lion, then it would have been difficult to apologize to yourself as you’re being dissolved in the lion’s stomach. The faster you spring into action — even if it’s based on the wrong reason — the better your chances of survival.
Learning ModelS HAVE TO Be Statistical, But Trained ModelS DoN't
It’s important to understand that learning models are the only components in machine learning that must be statistical. This is by definition. Because empirical learning is statistical, learning models need to be statistical, too.
This isn’t true for trained models, however. These models can be anything. From simple binary functions that answer yes / no questions, to something as complicated as the Standard Model — to solve whatever weird problems requiring this Lagrangian.
A trained model can even be a decision tree. That’s exactly what the random forest learning algorithm outputs. This algorithm randomly generates millions of decision trees ( hence the name, random forest ) and then makes decisions based on the aggregate of all the trees in the entire forest. The idea is that a bad choice suggested by a single individual tree would be drowned out by the symphony of all the other trees recommending the right one.
Sounds just like a real forest! If you stand in the middle of a fairy-tale setting and listen to the sounds of rustling leaves and chirping birds, you’ll hear Mother Nature tell you her story. The journeys she’s traveled, the adventures she’s had, and all the people she’s brutally murdered along the way — with forest fires, hurricanes, and earthquakes.
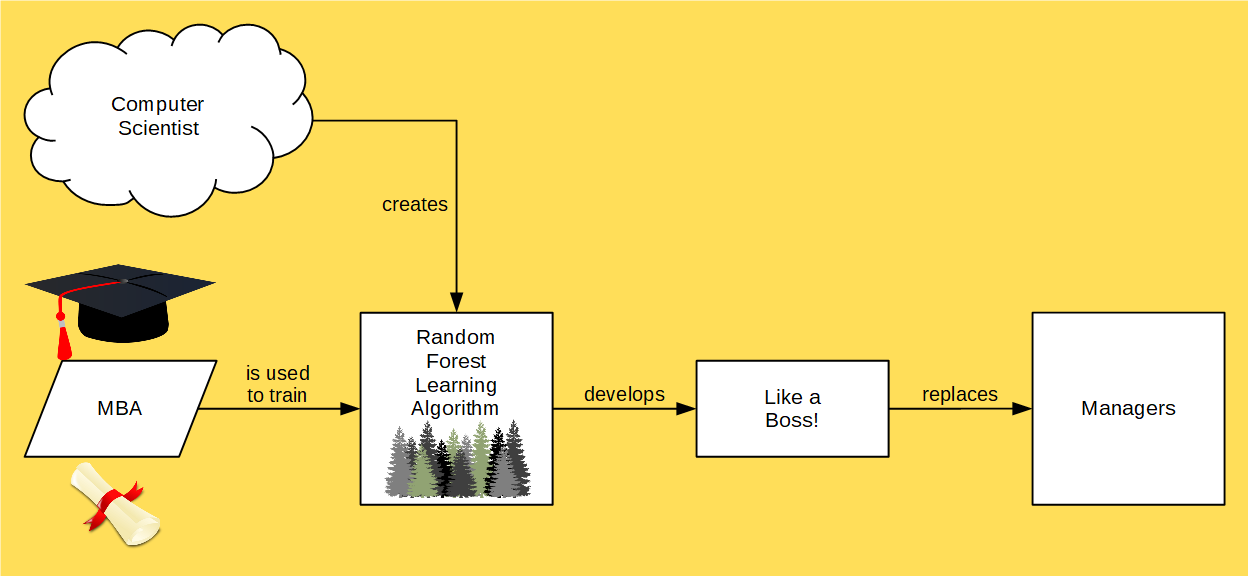
What do we call decision trees in our normal, daily conversations? Management skills. Yep! Thaat’s riight! MBA programs are specifically designed to activate the random forest learning algorithm in your head in order to get you to develop proper decision-making skills. The case studies, the coursework, the lectures, the group projects, etc., are all meant to help you grow a robust and sound forest. Unfortunately, from Jeffrey Skilling to Raj Rajaratnam, we’ve seen numerous examples where this isn’t always successful.
Machine Learning Uses Statistics — but It isn'T Statistics
This is where a lot of people get tripped up. They mistakenly believe that machine learning is just some “new-age”-y form of statistics that is supposed to replace “classical” statistics:
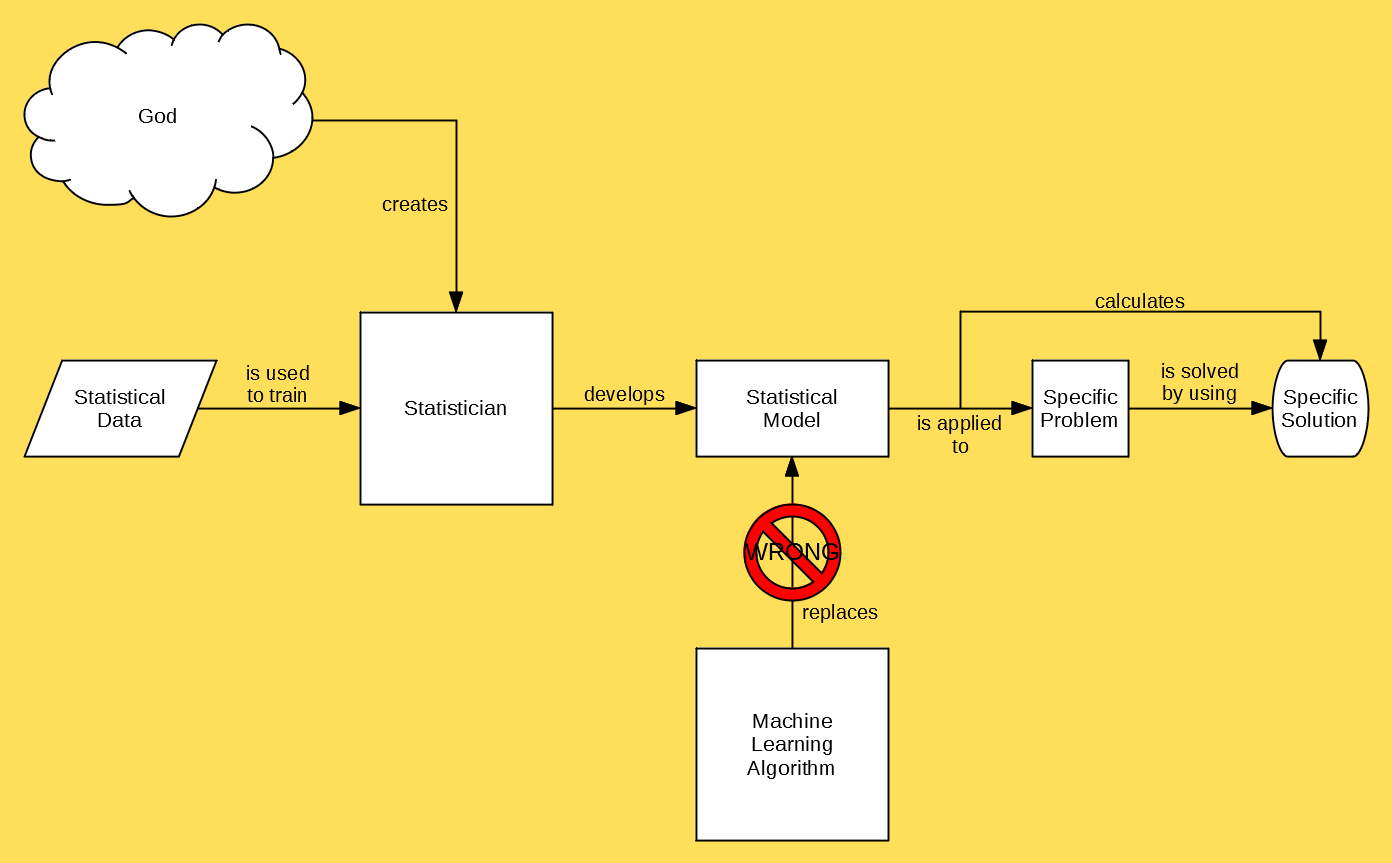
What many fail to realize is that in this scenario there are actually TWO statistical models — the first is the one that the statistician builds, and the second is the statistician herself. Machine learning is designed to replace the latter, NOT the former:
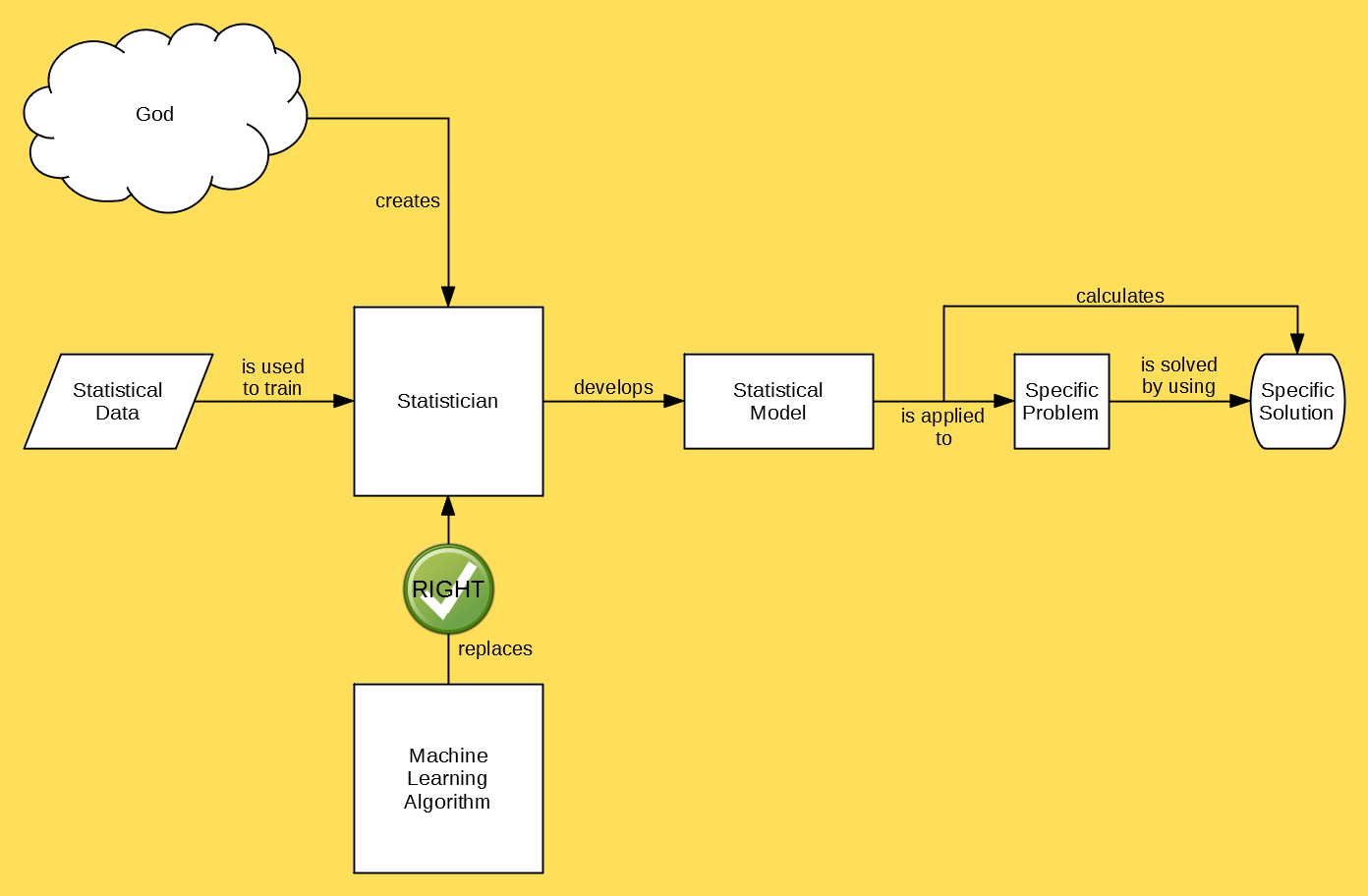
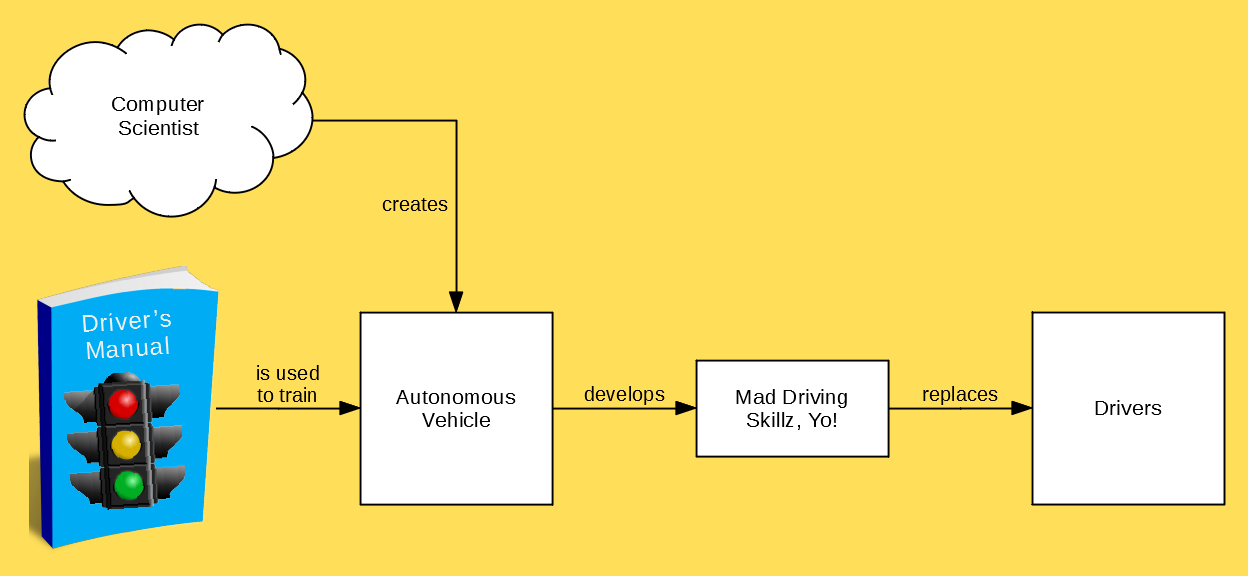
If you’re a statistician, then it must be very terrifying to realize that machines are going to replace you. But, there’s a teensy-tiny silver lining! Everyone else will be replaced by machines, too — so you won’t be alone in the unemployment line:
I do have some great news, though! There is one job — and ONLY one job — that machine learning can never replace. MINE!
No matter how sophisticated ML algorithms get, they will NEVER, EVER acquire the ability to replace their own gods. So, while you are starving to death, you can at least take comfort in knowing that I won’t be! I’ll still have a job, and my belly will be full!
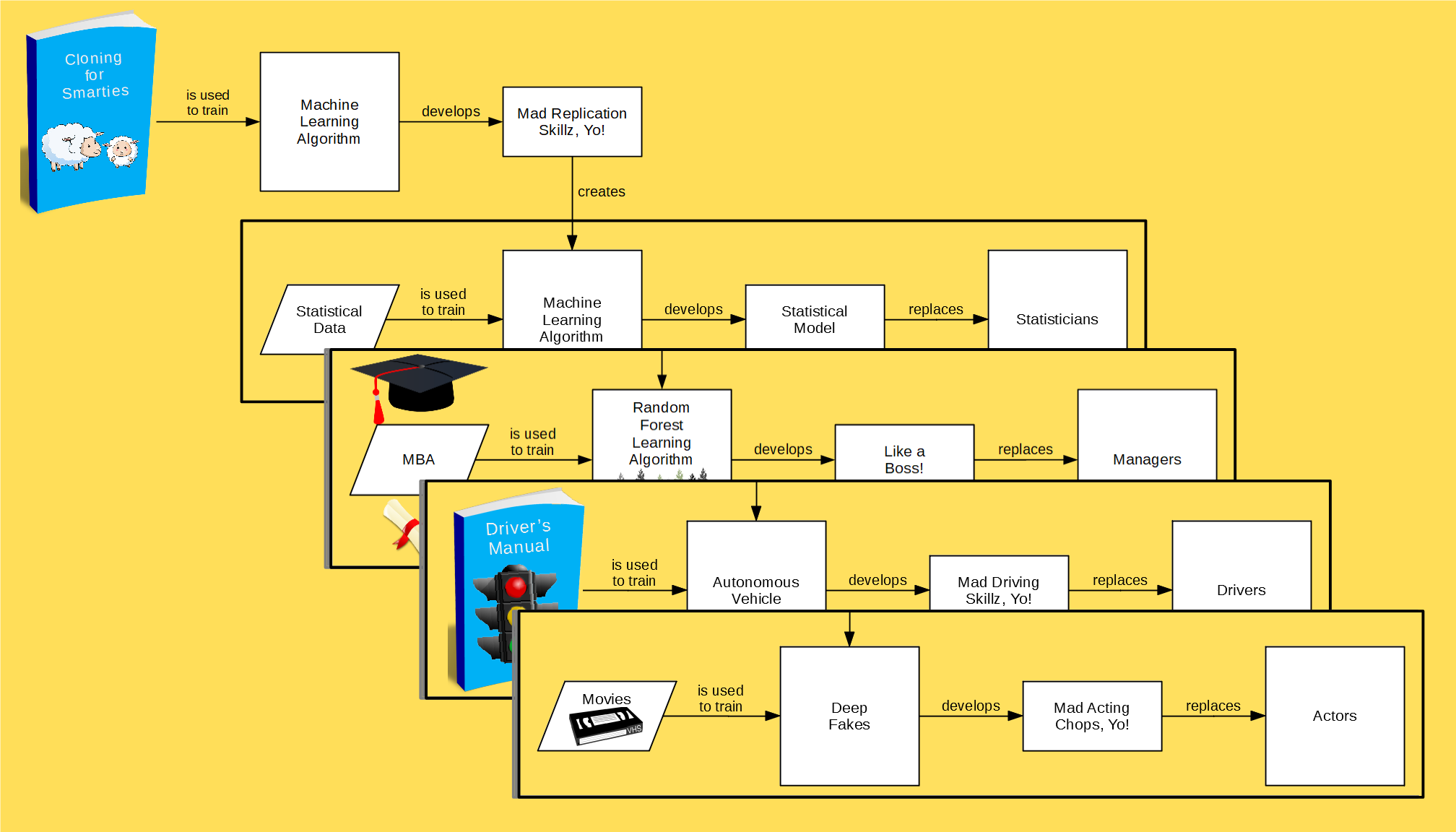
—— OHH, SHIT.